
A graph is a structure composed of vertices and edges. Formally, consider a set of vertices  with elements
with elements  and a set of edges
and a set of edges  composed of ordered pairs
composed of ordered pairs  of elements of . The graph
of elements of . The graph  is determined by the sets and . In the graph shown in Fig. 1 vertices are represented as circles and edges are represented as arrows. The set of vertices is
is determined by the sets and . In the graph shown in Fig. 1 vertices are represented as circles and edges are represented as arrows. The set of vertices is  and the set of edges is
and the set of edges is  . We will use
. We will use  to denote the number of vertices in the graph and, although not formally required, we will index vertices as
to denote the number of vertices in the graph and, although not formally required, we will index vertices as  .
.
The interest in graphs is that they are natural models of networks. If we interpret vertices as persons and edges as representing the relation “ considers a friend”, the graph is a model of a social network. If vertices denote employees and edges the relation “ is the boss of “, the graph represents a corporation’s hierarchy. If we consider that vertices represent web pages and edges links from page to page , the graph is model of the Web. Or, if vertices are associated with scientific papers and edges with the action “paper cites paper ,” the graph models the network of scientific knowledge.
considers a friend”, the graph is a model of a social network. If vertices denote employees and edges the relation “ is the boss of “, the graph represents a corporation’s hierarchy. If we consider that vertices represent web pages and edges links from page to page , the graph is model of the Web. Or, if vertices are associated with scientific papers and edges with the action “paper cites paper ,” the graph models the network of scientific knowledge.
An important problem in networks is to determine the importance of a node relative to other elements of the network. There are different ways of defining importance, but one that has broad applicability is to rank nodes according to their degree of connectivity. Think, e.g., of the network of scientific papers. It is quite likely that a paper that has received hundreds of citations is more important than a paper without any citations at all. In the graph in Fig. 1 this argument implies the reasonable conclusion that node 6, to whom 4 and 5 point, is more important than node 1 that lacks any incoming link.
 is its degree of connectivity. However, it is not only a matter of counting the number of links to , but also of pondering the importance of the nodes that point to . A link by node 4 is more important than a link from node 1.
is its degree of connectivity. However, it is not only a matter of counting the number of links to , but also of pondering the importance of the nodes that point to . A link by node 4 is more important than a link from node 1. An interesting conundrum arises in comparing vertices 2 and 3. While both nodes have only one incoming link, it seems reasonable to rank 3 higher than 2. Indeed, start noticing that 2 is clearly more important than 1 because while no vertex points to 1, 2 is at least pointed to by node 1. It then follows that it is reasonable to consider a link from node 2, which is received by 3, as more important than a link from node 1, which is received by 2, from where it follows that the rank of 3 is likely higher than the rank of 2. Similarly, compare nodes 4 and 5. While 5 is being pointed to by three nodes and 4 is pointed to by two nodes, it is not clear that 5 is in a better position than 4. As a matter of fact, it may well be that 4 is better positioned than 5 because the cumulative importance of the two nodes that point to her, namely 3 and 5 is larger than the cumulative importance of the three nodes that point to 5, namely 1, 2, and 4.
In summary, the rank of a given node, say , measured in terms of degree of connectivity, is determined by the set of nodes that point to it. However, there are two properties of this set that determine the rank of :
- (P1) The number of elements in this set.
- (P2) The rank of the members of this set.
The complementarity of properties (P1) and (P2) is most clear in a hierarchical network like the corporation’s graph. At the same level of the hierarchy, it is better to have more direct subordinates — Property (P1) — but the higher in the hierarchy the better — Property (P2). In terms of web pages, Property (P1) stresses the importance of having a large number of incoming links, while Property (P2) indicates that links from highly ranked pages are more relevant than links from obscure pages.
Accounting for Property (P2) is necessary but difficult because its definition is self-referential. To determine the rank a node it is necessary to know the rank of other nodes in the network, which in turn depend on the rank of the node in question. An elegant solution to overcome this problem is the use of a random walk in the graph that we describe next. The random walk model was originally proposed to rank scientific papers but its most popular application is the ranking of web pages by search engines.
Random walk in a graph
Consider a web surfer that visits a page and clicks on any of the page’s links at random. She repeats this process forever. What fraction of his time will be spent on a given page? The answer to this question is the rank assigned to the page. The same idea can be used to rank the nodes in any of the networks described above. In abstract we refer to the random web surfer as performing a random walk in a graph. It is clear that the ranks obtained from the number of visits of the random walker satisfy properties (P1) and (P2). The time spent by the random walker at node increases when the number of nodes pointing to increases, as required by Property (P1), and when the rank of the nodes pointing to increases, consistent with Property (P2).
For a formal problem definition of rank start defining  as the -th node’s neighborhood containing the indexes to which is pointing, i.e.,
as the -th node’s neighborhood containing the indexes to which is pointing, i.e.,  . Let
. Let  be the number of nodes in neighborhood of . Define finally
be the number of nodes in neighborhood of . Define finally  as the set of nodes that point to .
as the set of nodes that point to .
An outside agent approaches an arbitrary node at time  . From there, it jumps to one of the neighbors of at time
. From there, it jumps to one of the neighbors of at time  . The agent repeats this process forever. If the agent is visiting node
. The agent repeats this process forever. If the agent is visiting node  at time
at time  it will visit a node in the neighborhood
it will visit a node in the neighborhood  at time
at time  . The fraction of time the agent spends visiting node , is defined as the node’s rank. To express this mathematically define the indicator function
. The fraction of time the agent spends visiting node , is defined as the node’s rank. To express this mathematically define the indicator function  with value 1 when the agent visits at time and 0 otherwise. The rank
with value 1 when the agent visits at time and 0 otherwise. The rank  of node is then defined as
of node is then defined as
![\[r_{i} := \lim_{t\to\infty} \frac{1}{n} \sum_{m=1}^{n} I (A_{n}=i).\]](https://ese3030.seas.upenn.edu/wp-content/ql-cache/quicklatex.com-8e614fd2f7a122d62e1c99236ebfc5a7_l3.png "Rendered by QuickLaTeX.com")
Since we are considering equal probabilities of jumping to any neighbor, the probability  of transitioning from node to node is
of transitioning from node to node is
![\[P_{ij} := {\rm Pr}(i\to j) = \frac{1}{N_{i}}, \quad j \in n(i)\]](https://ese3030.seas.upenn.edu/wp-content/ql-cache/quicklatex.com-654182e4c45f96e36f013719521e0480_l3.png "Rendered by QuickLaTeX.com")
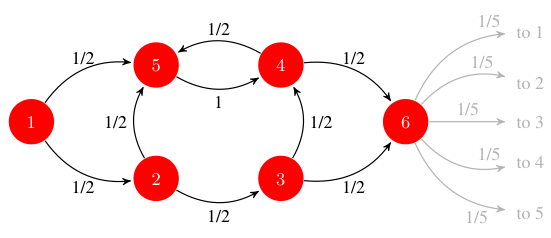
where, we recall, is the number of nodes in the neighborhood of ; see Fig. 2. We are now ready to build an algorithm to compute . We start with a randomly chosen node and jump equiprobably to any of its neighboring nodes  . The probability of selecting any of this nodes is
. The probability of selecting any of this nodes is  . We repeat this process a large number of times
. We repeat this process a large number of times  and keep track of the number of visits to each node. The rank is then approximated as the ratio between the number of visits to node and the total time , i.e.,
and keep track of the number of visits to each node. The rank is then approximated as the ratio between the number of visits to node and the total time , i.e.,
![\[r_{i} \approx \frac{1}{n} \sum_{m=1}^{n} I(A_{n}=i).\]](https://ese3030.seas.upenn.edu/wp-content/ql-cache/quicklatex.com-e91aba377737e665b4e31f9d449eda33_l3.png "Rendered by QuickLaTeX.com")
It is possible the agent reaches a dead-end node without any outgoing link. In such case, the next visit is to a different randomly selected node. This is equivalent to modifying the initial graph to include links from dead-end nodes to all other nodes in the graph.
This is certainly a possible algorithm, but we can obtain a faster version by exploiting the fact that these random visits can be modeled as a Markov chain (MC)
Markov chains
Notice that the probability of visiting node at time  , given that at time we are visiting node is independently of how we reached . This basic memoryless property implies that the stochastic process composed of node visits
, given that at time we are visiting node is independently of how we reached . This basic memoryless property implies that the stochastic process composed of node visits  is a MC. Exploiting this observation it is possible to build a more efficient algorithm to compute ranks .
is a MC. Exploiting this observation it is possible to build a more efficient algorithm to compute ranks .
Let  denote the probability that the outside agent is at node at time . It is possible to relate
denote the probability that the outside agent is at node at time . It is possible to relate  with the probabilities at time of those nodes that can transition into . Say that at time , the agent is at some node
with the probabilities at time of those nodes that can transition into . Say that at time , the agent is at some node  . Then, with probability
. Then, with probability  (note the reversion of subindices) the agent transitions into at time . Weighting this transition probability by the probability
(note the reversion of subindices) the agent transitions into at time . Weighting this transition probability by the probability  and summing over all possible transitions we can write
and summing over all possible transitions we can write
![\[p_{i}(n+1) = \sum_{j\in n^{-1}(i)} P_{ji}p_{j}(n) = \sum_{j=1}^{J} P_{ji}p_{j}(n)\]](https://ese3030.seas.upenn.edu/wp-content/ql-cache/quicklatex.com-00c609a1baec2a2f48184f583d0efd99_l3.png "Rendered by QuickLaTeX.com")
where in the second equality we used that  for all nodes that do not link to .
for all nodes that do not link to .
An interesting property of MCs is the existence of limit probabilities  under some conditions which we assume to hold. With further conditions it can be further proved that a property called ergodicity holds. Ergodicity implies that time average limits, as the one required to compute ranks coincide with the expected value of the event of interest. For ranks ergodicity implies that
under some conditions which we assume to hold. With further conditions it can be further proved that a property called ergodicity holds. Ergodicity implies that time average limits, as the one required to compute ranks coincide with the expected value of the event of interest. For ranks ergodicity implies that
![\[r_{i} = \lim_{n\to\infty} { E} \big[I (A_{n}=i) \big] = \lim_{n\to\infty} {\rm Pr}(A_{n}=i) = \lim_{n\to\infty}p_{i}(n)\]](https://ese3030.seas.upenn.edu/wp-content/ql-cache/quicklatex.com-fe03ae88fe83f63d1539e10898bec470_l3.png "Rendered by QuickLaTeX.com")
We can then equate the problem of computing ranks to the computation of the limiting probabilities. An alternative algorithm to compute nodes’ ranks is to run the probability updates in \eqref{eqn_prob_evolution_scalar} and approximate
![\[r_{i} \approx p_{i}(n)\]](https://ese3030.seas.upenn.edu/wp-content/ql-cache/quicklatex.com-be8c901c724708b57687b7cbb471efb3_l3.png "Rendered by QuickLaTeX.com")
for a sufficiently large . This latter algorithm converges much faster than the one based on random visits. The outcome of applying this ranking algorithm to the network in Fig. 1 is shown in Fig. 3.
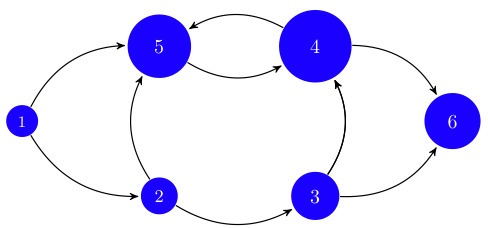
![r:=[0.04, 0.06, 0.07, 0.34, 0.26, 0.21]^{T}](https://ese3030.seas.upenn.edu/wp-content/ql-cache/quicklatex.com-ef75b4bfd03fcbe89fc75f35705556c9_l3.png "Rendered by QuickLaTeX.com") . In the figure, the area of the circles is proportional to their rank. Notice how 4 has a higher rank than 5 despite having fewer incoming links. This is consistent with the fact that links to 5 come from lower ranked nodes.
. In the figure, the area of the circles is proportional to their rank. Notice how 4 has a higher rank than 5 despite having fewer incoming links. This is consistent with the fact that links to 5 come from lower ranked nodes.